Demo Workflow & Decoupler#
Author: Severin Dicks
To run this notebook please make sure you have a working rapids environment with all nessaray dependencies. Run the data_downloader notebook first to create the AnnData object we are working with. In this example workflow we’ll be looking at a dataset of ca. 90000 cells from Quin et al., Cell Research 2020.
import scanpy as sc
import cupy as cp
import time
import rapids_singlecell as rsc
import warnings
warnings.filterwarnings("ignore")
import rmm
from rmm.allocators.cupy import rmm_cupy_allocator
rmm.reinitialize(
managed_memory=False, # Allows oversubscription
pool_allocator=False, # default is False
devices=0, # GPU device IDs to register. By default registers only GPU 0.
)
cp.cuda.set_allocator(rmm_cupy_allocator)
Load and Prepare Data#
We load the sparse count matrix from an h5ad file using Scanpy. The sparse count matrix will then be placed on the GPU.
data_load_start = time.time()
%%time
adata = sc.read("h5/adata.raw.h5ad")
CPU times: user 2.34 s, sys: 146 ms, total: 2.49 s
Wall time: 2.53 s
%%time
rsc.get.anndata_to_GPU(adata)
CPU times: user 57.9 ms, sys: 205 ms, total: 263 ms
Wall time: 262 ms
data_load_time = time.time()
print("Total data load and format time: %s" % (data_load_time - data_load_start))
Total data load and format time: 2.810950517654419
Preprocessing#
preprocess_start = time.time()
Quality Control#
We perform a basic qulitiy control and plot the results
%%time
rsc.pp.flag_gene_family(adata, gene_family_name="MT", gene_family_prefix="MT")
CPU times: user 5.76 ms, sys: 561 µs, total: 6.33 ms
Wall time: 6.19 ms
%%time
rsc.pp.flag_gene_family(adata, gene_family_name="RIBO", gene_family_prefix="RPS")
CPU times: user 5.68 ms, sys: 0 ns, total: 5.68 ms
Wall time: 5.58 ms
%%time
rsc.pp.calculate_qc_metrics(adata, qc_vars=["MT", "RIBO"])
CPU times: user 87.1 ms, sys: 6.5 ms, total: 93.6 ms
Wall time: 168 ms
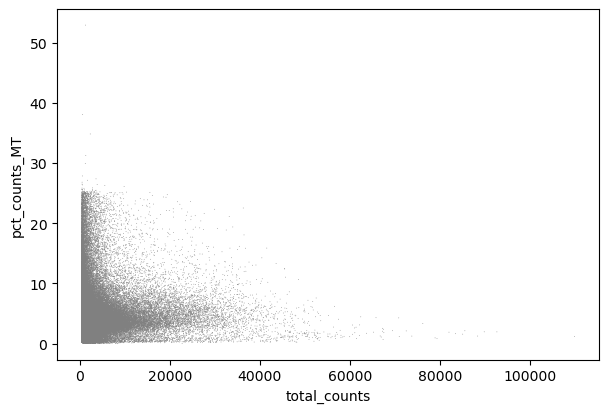
sc.pl.scatter(adata, x="total_counts", y="pct_counts_MT")
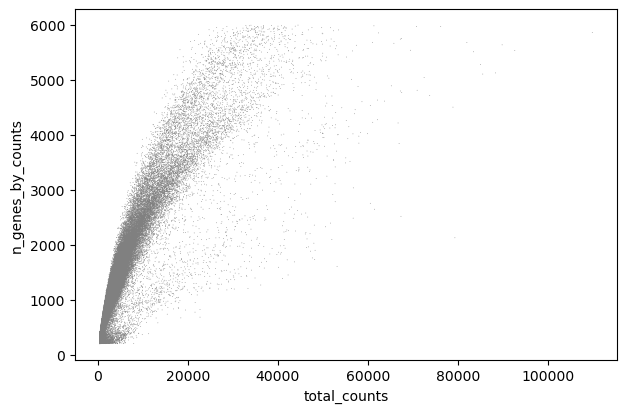
sc.pl.scatter(adata, x="total_counts", y="n_genes_by_counts")
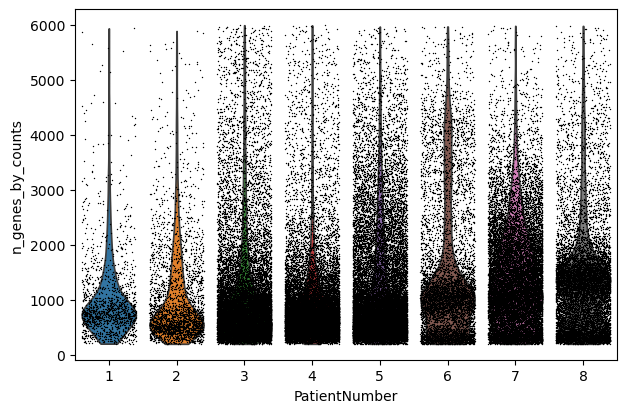
sc.pl.violin(adata, "n_genes_by_counts", jitter=0.4, groupby="PatientNumber")
sc.pl.violin(adata, "total_counts", jitter=0.4, groupby="PatientNumber")
sc.pl.violin(adata, "pct_counts_MT", jitter=0.4, groupby="PatientNumber")
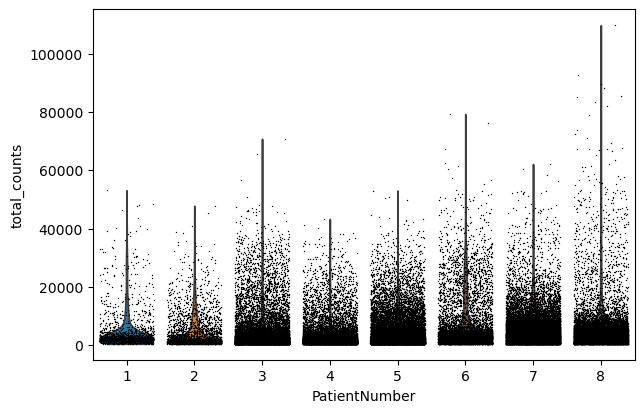
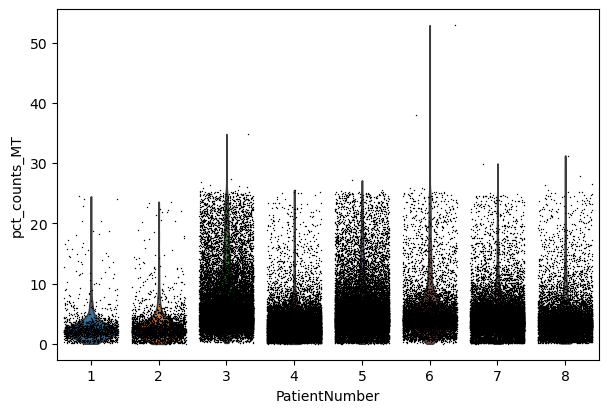
Filter#
We filter the count matrix to remove cells with an extreme number of genes expressed. We also filter out cells with a mitchondrial countent of more than 20%.
%%time
adata = adata[adata.obs["n_genes_by_counts"] < 5000]
adata = adata[adata.obs["pct_counts_MT"] < 20]
CPU times: user 16.8 ms, sys: 4.56 ms, total: 21.4 ms
Wall time: 20.6 ms
We also filter out genes that are expressed in less than 3 cells.
%%time
rsc.pp.filter_genes(adata, min_count=3)
filtered out 8034 genes based on n_cells_by_counts
CPU times: user 54.7 ms, sys: 27.6 ms, total: 82.3 ms
Wall time: 91.3 ms
The size of our count matrix is now reduced.
adata.shape
(91068, 25660)
Normalize#
We normalize the count matrix so that the total counts in each cell sum to 1e4.
%%time
rsc.pp.normalize_total(adata, target_sum=1e4)
CPU times: user 239 µs, sys: 1.09 ms, total: 1.33 ms
Wall time: 7.03 ms
Next, we data transform the count matrix.
%%time
rsc.pp.log1p(adata)
CPU times: user 7 µs, sys: 3.01 ms, total: 3.02 ms
Wall time: 2.92 ms
Select Most Variable Genes#
Now we search for highly variable genes. This function only supports the flavors cell_ranger seurat seurat_v3 and pearson_residuals. As you can in scanpy you can filter based on cutoffs or select the top n cells. You can also use a batch_key to reduce batcheffects.
In this example we use cell_ranger for selecting highly variable genes based on the log normalized counts in .X
%%time
rsc.pp.highly_variable_genes(adata, n_top_genes=5000, flavor="cell_ranger")
CPU times: user 256 ms, sys: 27.6 ms, total: 284 ms
Wall time: 316 ms
Now we safe this version of the AnnData as adata.raw.
%%time
adata.raw = adata
CPU times: user 64.4 ms, sys: 52.9 ms, total: 117 ms
Wall time: 116 ms
Now we restrict our AnnData object to the highly variable genes.
%%time
rsc.pp.filter_highly_variable(adata)
CPU times: user 116 ms, sys: 118 ms, total: 234 ms
Wall time: 234 ms
Next we regress out effects of counts per cell and the mitochondrial content of the cells. As you can with scanpy you can use every numerical column in .obs for this.
%%time
rsc.pp.regress_out(adata, keys=["total_counts", "pct_counts_MT"])
CPU times: user 531 ms, sys: 663 ms, total: 1.19 s
Wall time: 1.23 s
Scale#
Finally, we scale the count matrix to obtain a z-score and apply a cutoff value of 10 standard deviations.
%%time
rsc.pp.scale(adata, max_value=10)
CPU times: user 29 ms, sys: 3.58 ms, total: 32.6 ms
Wall time: 45.4 ms
Now we move .X out of the GPU.
%%time
rsc.get.anndata_to_CPU(adata)
CPU times: user 153 ms, sys: 103 ms, total: 256 ms
Wall time: 256 ms
preprocess_time = time.time()
print("Total Preprocessing time: %s" % (preprocess_time - preprocess_start))
Total Preprocessing time: 6.157665252685547
We have now finished the preprocessing of the data.
Clustering and Visualization#
Principal component analysis#
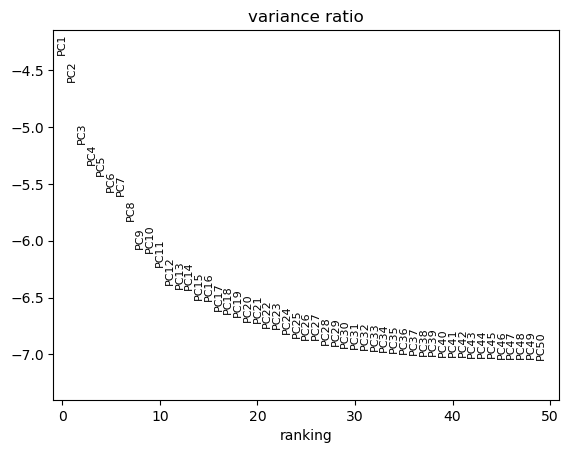
We use PCA to reduce the dimensionality of the matrix to its top 100 principal components. We use the PCA implementation from cuMLs.
%%time
rsc.tl.pca(adata, n_comps=100)
CPU times: user 1.41 s, sys: 582 ms, total: 1.99 s
Wall time: 2 s
We can use scanpy pca_variance_ratio plot to inspect the contribution of single PCs to the total variance in the data.
sc.pl.pca_variance_ratio(adata, log=True, n_pcs=100)
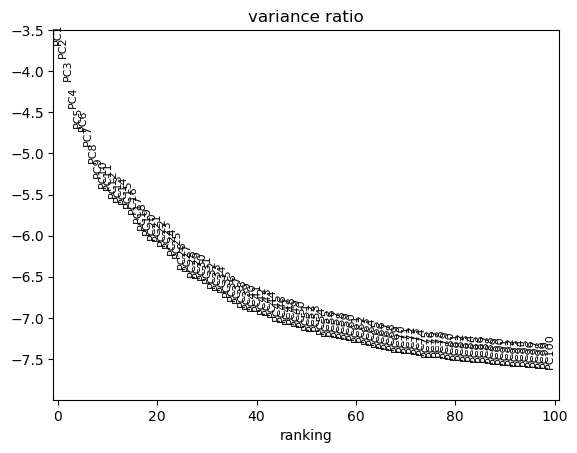
Computing the neighborhood graph and UMAP#
Next we compute the neighborhood graph using rsc.
Scanpy CPU implementation of nearest neighbor uses an approximation, while the GPU version calculates the exact graph. Both methods are valid, but you might see differences.
%%time
rsc.pp.neighbors(adata, n_neighbors=15, n_pcs=40)
CPU times: user 243 ms, sys: 27.9 ms, total: 271 ms
Wall time: 278 ms
Next we calculate the UMAP embedding using rapdis.
%%time
rsc.tl.umap(adata)
CPU times: user 250 ms, sys: 13.3 ms, total: 263 ms
Wall time: 263 ms
Clustering#
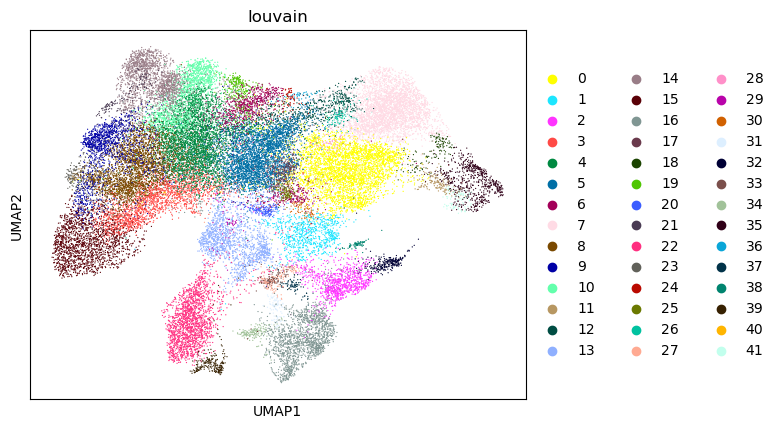
Next, we use the Louvain and Leiden algorithm for graph-based clustering.
%%time
rsc.tl.louvain(adata, resolution=0.6)
CPU times: user 3.36 s, sys: 815 ms, total: 4.18 s
Wall time: 6.06 s
%%time
rsc.tl.leiden(adata, resolution=0.6)
CPU times: user 414 ms, sys: 564 ms, total: 979 ms
Wall time: 981 ms
%%time
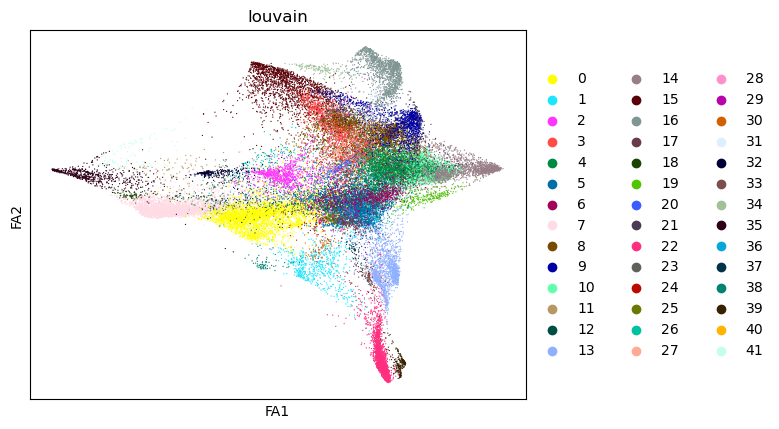
sc.pl.umap(adata, color=["louvain", "leiden"], legend_loc="on data")

CPU times: user 709 ms, sys: 161 ms, total: 869 ms
Wall time: 691 ms
sc.pl.umap(adata, color=["CellType", "PatientNumber"])
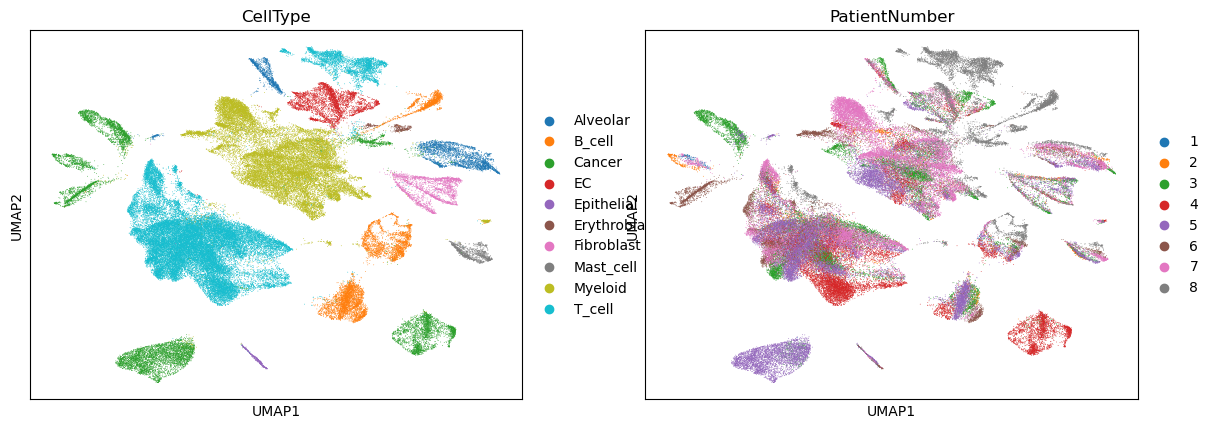
TSNE + k-Means#
Next we use TSNE on the GPU to visualize the cells in two dimensions. We also perform k-Means clustering of the cells into 8 clusters.
%%time
rsc.tl.tsne(adata, n_pcs=40, perplexity=30, early_exaggeration=12, learning_rate=200)
[W] [17:02:59.730800] # of Nearest Neighbors should be at least 3 * perplexity. Your results might be a bit strange...
CPU times: user 1.36 s, sys: 1.35 s, total: 2.71 s
Wall time: 2.71 s
rsc.tl.kmeans(adata, n_clusters=8)
%%time
sc.pl.tsne(adata, color=["kmeans"], legend_loc="on data")

CPU times: user 300 ms, sys: 156 ms, total: 456 ms
Wall time: 274 ms
sc.pl.tsne(adata, color=["CellType", "PatientNumber"])

Differential expression analysis#
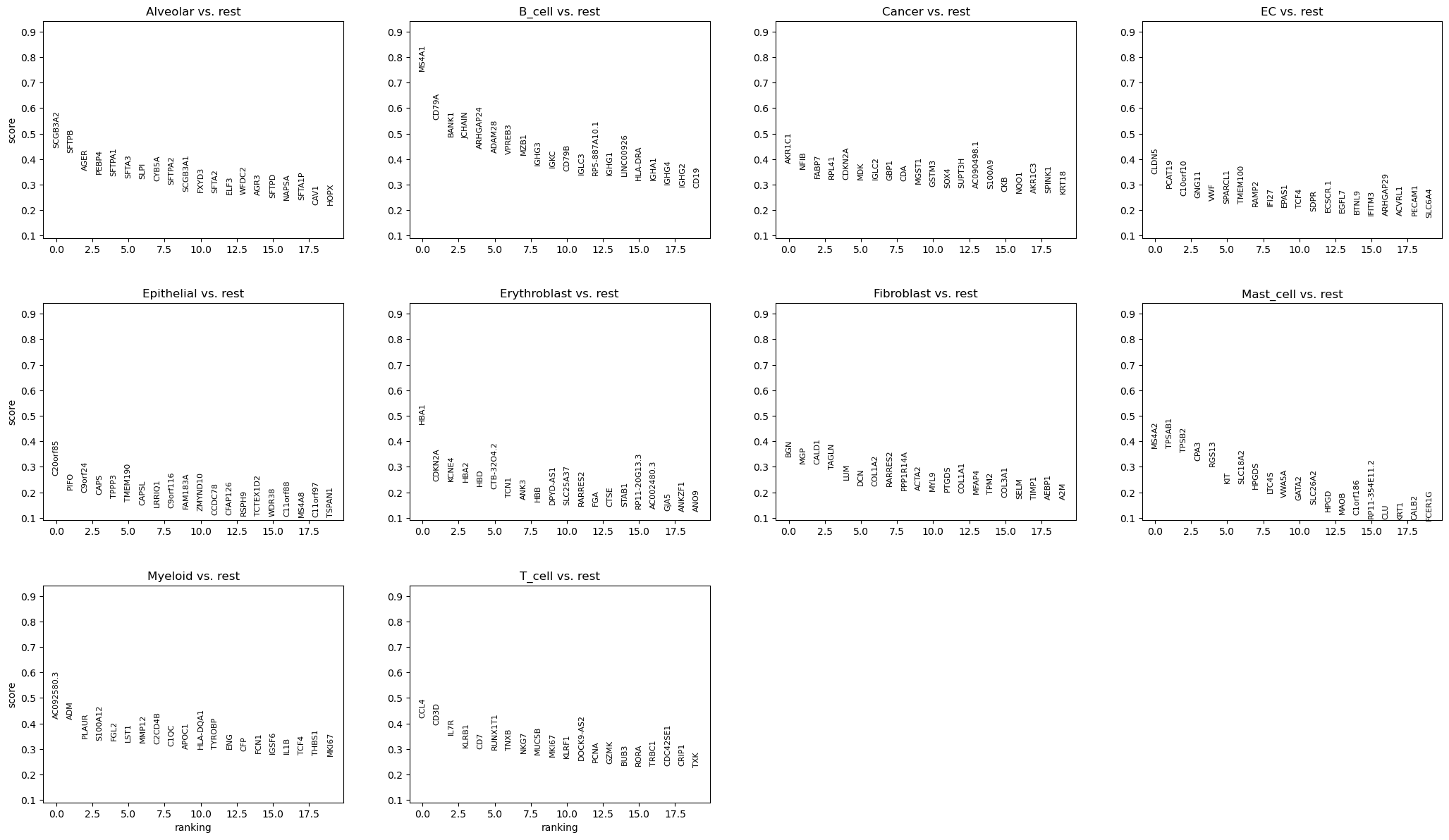
We now use logistic regression to compute a ranking for highly differential genes in each Louvain cluster.
We use logistic regression to identify the top 50 genes distinguishing each cluster.
%%time
rsc.tl.rank_genes_groups_logreg(adata, groupby="CellType", use_raw=False)
[W] [17:03:06.404040] L-BFGS stopped, because the line search failed to advance (step delta = 0.000000)
CPU times: user 2.24 s, sys: 638 ms, total: 2.88 s
Wall time: 2.91 s
sc.pl.rank_genes_groups(adata)
post_time = time.time()
print("Total Postprocessing time: %s" % (post_time - preprocess_time))
Total Postprocessing time: 18.99196195602417
Diffusion Maps#
With cupy 9 its possible to compute Eigenvalues of sparse matrixes. We now create a Diffusion Map of the T-Cells to look at trajectories.
First we create a subset of only the T-Cells
tdata = adata[adata.obs["CellType"] == "T_cell", :].copy()
We can repeat the dimension reduction, clustering and visulatization.
%%time
rsc.pp.pca(tdata, n_comps=50)
sc.pl.pca_variance_ratio(tdata, log=True, n_pcs=50)
CPU times: user 833 ms, sys: 497 ms, total: 1.33 s
Wall time: 1.15 s
%%time
rsc.pp.neighbors(tdata, n_neighbors=15, n_pcs=20)
rsc.tl.umap(tdata)
rsc.tl.louvain(tdata)
CPU times: user 397 ms, sys: 322 ms, total: 719 ms
Wall time: 721 ms
sc.pl.umap(tdata, color=["louvain"])
As stated before Diffusion Maps have become an integral part of single cell analysis.
%%time
rsc.tl.diffmap(tdata)
CPU times: user 347 ms, sys: 1.29 s, total: 1.63 s
Wall time: 192 ms
sc.pl.diffmap(tdata, color="louvain")
%%time
rsc.tl.draw_graph(tdata)
CPU times: user 333 ms, sys: 9.48 ms, total: 342 ms
Wall time: 346 ms
sc.pl.draw_graph(tdata, color="louvain")
After this you can use X_diffmap for sc.pp.neighbors and other functions.
print("Total Processing time: %s" % (time.time() - preprocess_start))
Total Processing time: 29.676725387573242
Decoupler-GPU#
Here I introduce 2 functions of the decoupler package that have been accelerated with cupy: mlmand wsum.
You can use the same nets that you would use with the CPU implementation.
import decoupler as dc
net = dc.get_dorothea(organism="human", levels=["A", "B", "C"])
%%time
rsc.dcg.run_mlm(
mat=adata, net=net, source="source", target="target", weight="weight", verbose=True
)
4 features of mat are empty, they will be removed.
Running mlm on mat with 91068 samples and 25656 targets for 297 sources.
CPU times: user 8.68 s, sys: 2.93 s, total: 11.6 s
Wall time: 11.7 s
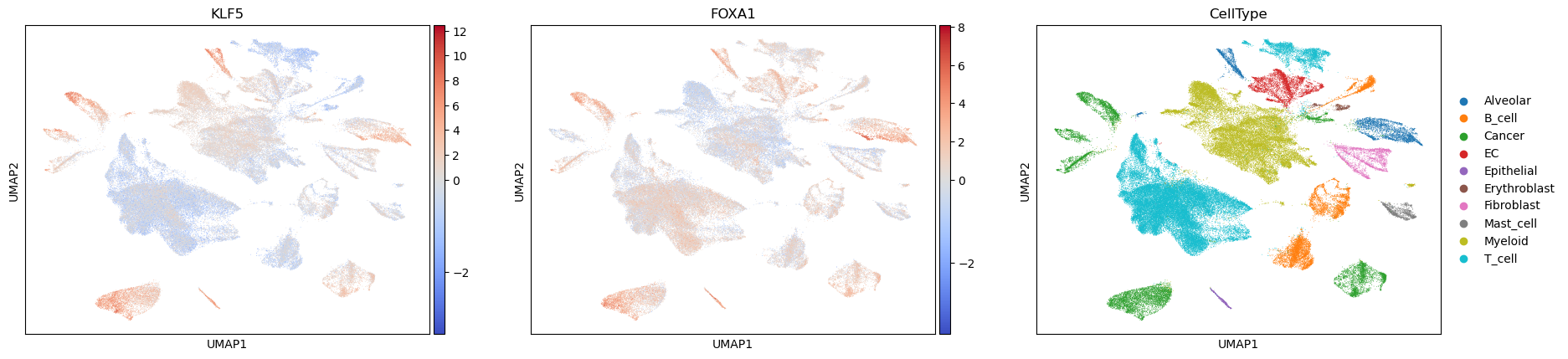
acts_mlm = dc.get_acts(adata, obsm_key="mlm_estimate")
sc.pl.umap(acts_mlm, color=["KLF5", "FOXA1", "CellType"], cmap="coolwarm", vcenter=0)
model = dc.get_progeny(organism="human", top=100)
%%time
rsc.dcg.run_wsum(
mat=adata,
net=model,
source="source",
target="target",
weight="weight",
verbose=True,
)
4 features of mat are empty, they will be removed.
Running wsum on mat with 91068 samples and 25656 targets for 14 sources.
CPU times: user 19.3 s, sys: 4.38 s, total: 23.6 s
Wall time: 23.8 s
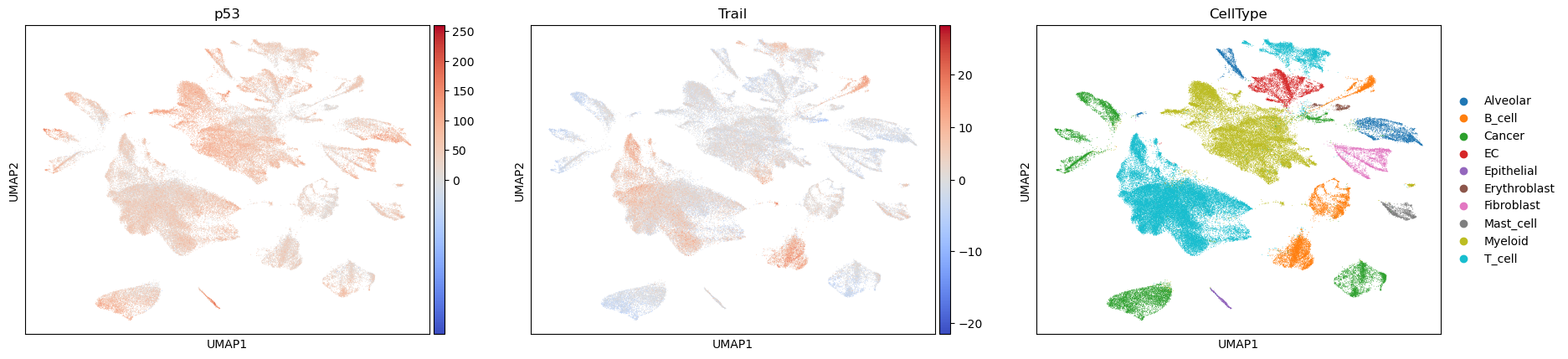
acts_wsum = dc.get_acts(adata, obsm_key="wsum_estimate")
sc.pl.umap(acts_wsum, color=["p53", "Trail", "CellType"], cmap="coolwarm", vcenter=0)